
July 3, 2026 · 10:34 AM
LongCat-2.0:美团把万亿模型押在代码 Agent 上
解读美团 LongCat-2.0:它的重点不是单纯堆到 1.6T 参数,而是在国产 AI ASIC 集群上把 1M 上下文、稀疏注意力和多专家后训练组合成面向代码 Agent 的工程路线。文章同时说明官方评测的亮点、开源状态和仍需复测的边界。

LongCat-2.0 的看点不只在 1.6T 参数。更关键的是,美团把这次发布写成了一次完整的工程验证:在国产 AI ASIC 集群上从零训练、部署一个面向代码 Agent 的 MoE 模型,并把 1M 上下文、稀疏注意力、零计算专家和多专家后训练放到同一条路线上。官方中文博客称,它在 2026 年 6 月 30 日发布,总参数 1.6T,平均激活约 48B,动态激活范围 33B 到 56B,并将对外开源。1
这篇解读先把一个边界说清楚:官方材料已经给出了技术博客、Hugging Face 页面、GitHub / API 入口,但 Hugging Face 模型卡截至页面抓取时仍写着「Model weights coming soon」,且没有接入推理服务。2 所以它现在更像一次完整技术路线披露和开放入口预告,真正的开源可复现程度,还要等权重、训练细节和第三方评测逐步落地。
先看结论:LongCat-2.0 押的是代码 Agent
LongCat-2.0 不是通用聊天模型换壳。官方反复强调的目标很具体:让模型在真实 Agentic Coding 任务中完成代码理解、生成和执行。Agentic Coding 可以理解为「模型不只是补全一段代码,而是读仓库、看文档、调用工具、运行命令、改错再提交」这一类长链路软件任务。中文博客列出的内测案例也集中在 SQL Agent、代码库迁移、完整应用开发、Three.js 交互演示和小说工厂等工作流。1
这解释了它为什么同时强调三个能力:
- 长上下文:原生支持 1M 上下文,让模型一次看到更大的项目、文档和任务轨迹。1
- 稀疏计算:MoE、零计算专家、N-gram Embedding 和 LongCat Sparse Attention 都是在控制 1.6T 参数模型的实际计算账。3
- 后训练分工:MOPD 把 Agent、Reasoning、Interaction 三组专家蒸馏到最终模型里,分别处理工具调用、推理和交互对齐。3
如果只看「1.6T」这个数字,很容易误读这次发布。LongCat-2.0 真正想证明的是:万亿级 MoE 不一定只能追求更大的密集计算;它也可以通过更细的路由、更长的上下文和更工程化的部署,让代码 Agent 任务跑得住。
架构:把长上下文的索引成本降下来
LongCat-2.0 的注意力机制叫 LongCat Sparse Attention,简称 LSA。官方说它是在 DeepSeek Sparse Attention 思路上继续改进,重点不是把所有 token 都看一遍,而是用索引器挑出更值得关注的 token。英文技术博客把 LSA 拆成三块:Streaming-aware Indexing 让访问更连续,Cross-Layer Indexing 让相邻层复用一次索引,Hierarchical Indexing 先粗召回再细筛。3
这几个词听起来像系统论文里的缩写,但背后的问题很朴素:1M 上下文下,模型不能每次都按平方级成本处理所有 token。Agent 写代码时,前面几万行仓库、依赖文档和失败日志都可能有用,但每一步生成又只需要其中一小部分。LSA 的作用,是让模型在长上下文里先快速定位,再把计算集中到更可能影响下一步决策的位置。
N-gram Embedding 是另一条省账路线。LongCat-2.0 配置了 5-gram,并放入 135B N-gram Embedding 参数;官方解释说,在 MoE 稀疏度已经接近 97% 时,继续堆专家的边际收益变小,N-gram Embedding 这种稀疏维度能更有效地利用参数预算。3 这不是常见的「参数越多越好」叙事,而是在说参数放在哪里更值钱。
国产算力不是背景板,是这次发布的工程主线
美团中文博客说,LongCat 团队从 2023 年开始探索国产算力,从千卡起步,最后在五万卡集群上完成万亿参数模型的全流程训练与推理;预训练数据规模超过 30T tokens。1 英文博客的表述更偏工程侧:LongCat-2.0 在 50K 以上 AI ASIC 上预训练,围绕确定性、故障恢复、并行策略、显存管理和推理解耦部署做了系统优化。3
这里最有信息量的,不是「国产」两个字本身,而是官方披露的几个工程指标:月均日故障率降低 70% 以上,训练 MFU 提升 1.5 倍,稳态日吞吐超过 1T tokens/day。1 这些数字指向的是大规模训练最难看的部分:掉卡、通信异常、显存压力、算子精度和恢复成本。
换句话说,LongCat-2.0 不只是一个模型发布,也是在展示一套替代硬件平台上的训练和推理栈。对国内团队来说,这比单个 benchmark 更值得盯,因为它关系到后续大模型训练是否能摆脱单一硬件生态的约束。
评测:代码项有亮点,但不是全面压制
官方评测里,LongCat-2.0 在 SWE-bench Pro 得到 59.5,中文博客称高于 Gemini 3.1 Pro 的 54.2、GPT-5.5 的 58.6 和 Claude Opus 4.6 的 57.3;在 SWE-bench Multilingual 上得到 77.3,接近 Claude Opus 4.6 的 77.8;在 Terminal-Bench 2.1 上得到 70.8。1
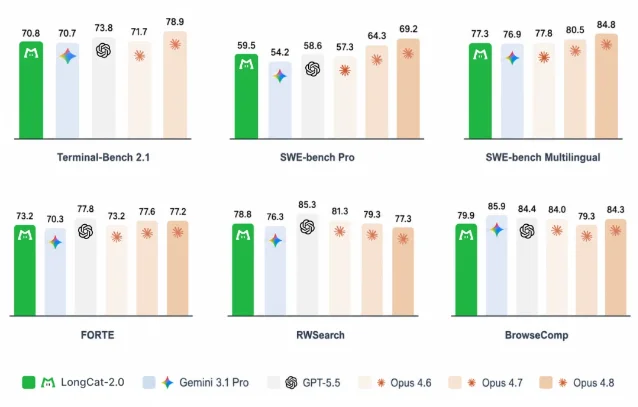
英文技术博客给出了更完整的表格,也暴露了边界:Terminal-Bench 2.1 上,GPT-5.5 是 73.8,Claude Opus 4.8 是 78.9;BrowseComp 上,Gemini 3.1 Pro 是 85.9,GPT-5.5 是 84.4,而 LongCat-2.0 是 79.9。3 这意味着它在代码修复和多语言软件任务上值得认真测试,但不能直接推导成「所有 Agent 场景都领先」。
评测口径也要留意。英文博客说明,除带星号的外部报告指标外,其余成绩是在官方统一 harness 下测得;SWE-bench 系列还标注了通过 Claude Code 运行、沙箱规格、温度和问题任务修正等条件。3 这些细节很重要,因为 Agent benchmark 对工具环境、超时设置、失败重试和上下文管理高度敏感。同一个底座模型,换一套执行框架,成绩可能会变。
现在该怎么判断它的价值
如果你做的是代码 Agent、仓库迁移、企业内部办公自动化,LongCat-2.0 值得放进测试清单。它的卖点不是单轮回答,而是长上下文、多步骤工具调用和工程执行。官方案例里的 SQL Agent、代码库迁移和完整应用开发,都指向同一个使用方式:把模型当成能读材料、能调用工具、能连续交付的工作节点。1
但真正评估前,至少要补三件事:
- 看权重和许可证是否已经实际可用。Hugging Face 页面写着 MIT license,同时也写着权重即将到来;这两句话放在一起,说明开放状态还没完全闭环。2
- 用自己的代码仓库和工具链复测,而不是只看 SWE-bench。Agentic Coding 的失败往往出在依赖安装、环境理解、命令执行和长日志定位上。
- 分开看「模型能力」和「系统能力」。LongCat-2.0 的很多优势来自上下文、推理服务、专家并行和部署调度;如果只拿裸模型离线跑小任务,未必能复现官方工作流效果。
LongCat-2.0 这次最硬的信号,是美团把国产算力训练栈、万亿 MoE、1M 上下文和代码 Agent 放进了同一个发布包。读者接下来要盯的,不是下一张更漂亮的榜单,而是权重是否按承诺放出、第三方能否复现代码 Agent 成绩,以及这些长上下文工作流在真实仓库里会卡在哪些地方。
More from this channel
Related content
- Sign in to comment.